Lexical Analyzer nicht nur für Αλτγριέχισχ* mit lex/flex
Querverweise:- CSV-Verarbeitung für den Desktop
- Generierung formatierter Excel-Dateien aus erweiterten csv-Dateien mit Ruby
- Pivotierung von csv-Dateien
- Wechselseitige Konvertierung von csv- und sc-Dateien


*: Altgriechisch
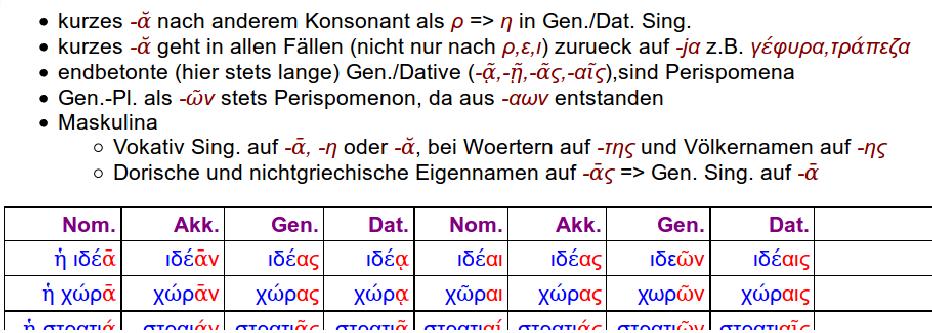
Grundfunktion
Ein Lexical-Analzyer oder Scanner kann Anwendung finden, wo klassische Scriptlösungen zwar nicht unmöglich, jedoch schwierig werden.Dies sollen die folgenden Beispiele verdeutlichen:
- Wandlung von CSV-Dateien mit Kommata und Hochkommata in solche mit Semikola ohne Hochkommata
- Dies ist bereits die einfachste Form eines fortgeschrittenen 2-Zustandsscanners
- Einfügen von Altgriechisch-Text als Overlay des privaten Cloudreaders
- Eine alternative Anwendung des Lexers/Scanners im Backend ist der Altgriechisch-Online-Konverter
- Suche in eigenem Online-Altgriechisch-Wörterbuch
- Ein weiterer Scanner mit 2 Zuständen für das Schreiben Deutsch-Griechischer Texte (z.B. Grammatiken) ist schließlich unter Erweiterte Funktion beschrieben.
CSV-Wandlung
Um CSV-Dateien mit Skripten (bash, awk, sed) zu verarbeiten, sollte das Spaltentrennzeichen nicht innerhalb von Spalteninhalten vorkommen. Der Default-Export von Microsoft-Excel etwa verwendet Semikola als Spaltentrenner, so dass Kommata innnerhalb von Texten oder Zahlen nicht quoted sein müssen. Für Script-Anwendungen ist dagegen sehr aufwendig, eine CSV-Datei mit einer Mischung spaltentrennender Kommata und in Hochkommata eingeschlossener echter Kommata (z.B. als Dezimaltrenner bei Zahlen oder Trenner von Nach- und Vornamen) korrekt zu verarbeiten, wie sie z.B. als Download firmeneigener Online-Anwendungen ausschließlich angeboten werden.- Schlechtes CSV: "Dr. Breinlinger, Heinz","32,68",Einzahlung
- Gutes CSV: Dr. Breinlinger, Heinz;32,68;Einzahlung
Der zielführende Algorithmus, für welchen ein Lexer prädestiniert ist, ahmt den Scan des menschlichen Betrachters Zeichen für Zeichen nach, wechselt bei öffnenden wie schließenden Hochkommata schlicht die Ausgabe-/Ersetzungsregel für Hochkommata und ist ebenso prägnant wie als C-Code effizient.

Der lex/flex-Scanner beginnt im Zustand OUTSIDESTRING, in welchem Kommata als Semikola, alle anderen Zeichen außer Hochkommata unverändert ausgegeben werden und das nächste (erste) gefundene Hochkomma in den Zustand INSIDESTRING wechseln lässt, welcher im Unterschied zum vorigen auch Kommata unverändert ausgibt und bei erneutem Hochkomma wiederum in den Zustand OUTSIDESTRING wechselt.
Kommentierungs- und Suchfunktion auf Webseiten
Für die private Onlinebibliothek werden 2 Funktionen benötigt, um in jeweils digitalisierten Privatkopien- altgriechisch zu kommentieren

- altgriechische Worte nachzuschlagen (Wörterbuchfunktion)

Als Server-basierter Altgriechisch-Konverter wurde bereits ein sed-Script vorgestellt, welches aus einfachem Pseudo-Code polytonisches Griechisch für HTML-Seiten erzeugt.
Dessen Kniffligkeit liegt jedoch unter anderem darin, dass
- Ketten aus bis zu 5 Zeichen Pseudocode ein einziges griechisches Zeichen beschreiben
- einzelne Pseudocodes jedoch Teilmengen voneinander darstellen wie im folgenden Beispiel, dessen Darstellungen sich lediglich im iota subscriptum unterscheiden:
- spiritus asper + akut + iota subscriptum + eta: (/|h wird zu ᾕ
- spiritus asper + akut + eta: (/h wird zu ἥ
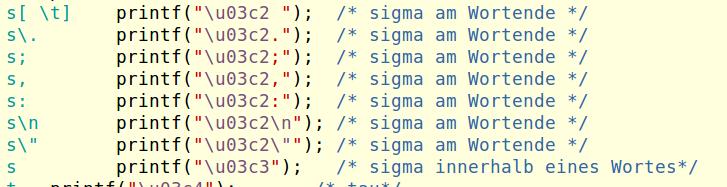
- das griechische Sigma innerhalb eines Wortes durch ein anderes Zeichen dargestellt wird als an/vor Wort-/Satzenden oder Interpunktion
Für diese Art Problemstellung
- n:1-Abbildungsfunktion von Mehrzeichen-Pseudocode auf Einzelzeichen bei
- überlappenden Abbildungsregeln
Anwendung 1: Altgriechische Kommentarfunktion
Daher wurde für die Kommentierungsfunktion des privaten Cloudreaders (Interaktives Einfügen altgriechischer Notizen in digitalisierte Privatkopien der Online-Bibliothek)
aus lex/flex ein Lexical-Analyzer entwickelt, welcher via PHP/Ajax/Javascript aus Pseudocode des Altgriechisch-Konverters Unicode für polytonisches Griechisch in ein die Buchseite überlagerndes HTML5-Canvas-Objekt einfügt.
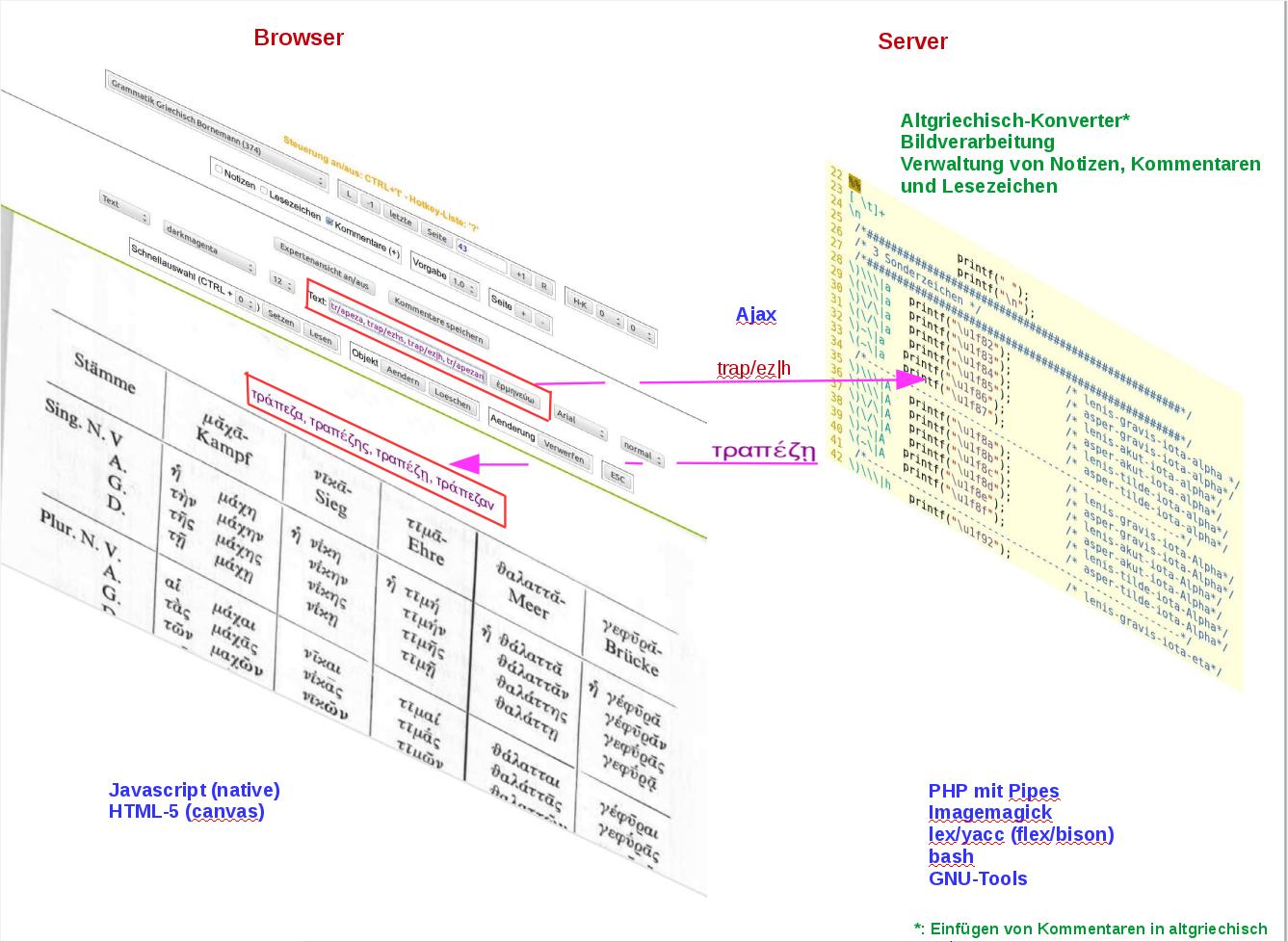
Als Konfigurationsdatei des Scanners genügt im Unterschied zu obigem sed-Script eine nun beliebige Reihenfolge von Regeln, hier 2 Beispielauszüge für
4-teiligen Meta-Code mit zusätzlichem Escape-\ für Braces, Pipe und Backslash, da letztere gleichzeitig Scanner-eigene Sonderzeichen darstellen
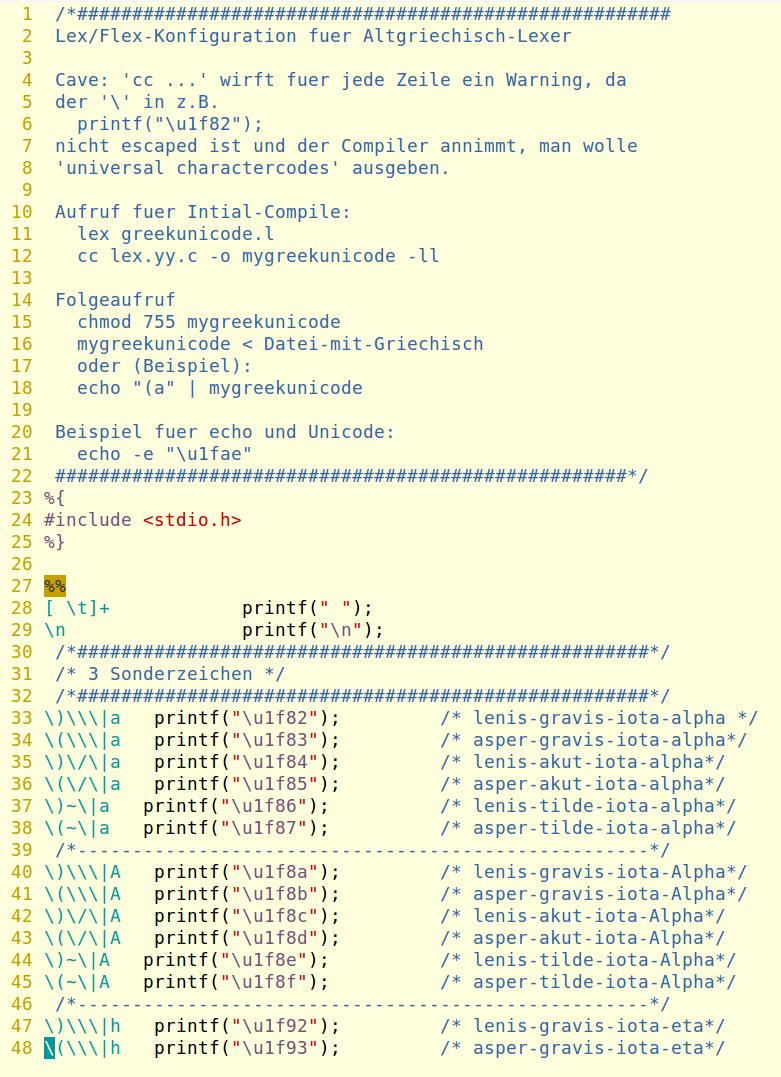
und die verschiedene Behandlung von ς und σ
Anwendung 2: Nachschlagen altgriechischer Worte in Online-Wörterbuch
Ein ähnliche Problemstellung besteht in der Aufgabe, für ein ebenfalls als Privatkopie digitalisiertes Online-Griechisch-Wörterbuch eine seitengenaue Indizierung mit Suchfunktion bereitzustellen.- Griechische Worte müssen einerseits ohne Sonderzeichen (Spiritus, Akzente, ...) als Pseudocode in der Suchmaske eingebbar sein,
- andererseits im Vergleich mit einer serverseitigen Indexdatei ebendort seitengenau
- trotz n:1-Beziehung codierender zu codierter Zeichen und
- abweichender Zeichenreihenfolgen der griechischen und römischen Alphabete gefunden werden !
- (nicht nur) das Linux-eigene sort verwendet nun mal das römische Alphabet
Eine Index-Suchfunktion muss also das Abbildungs- UND Sortierreihenfolgenproblem lösen !
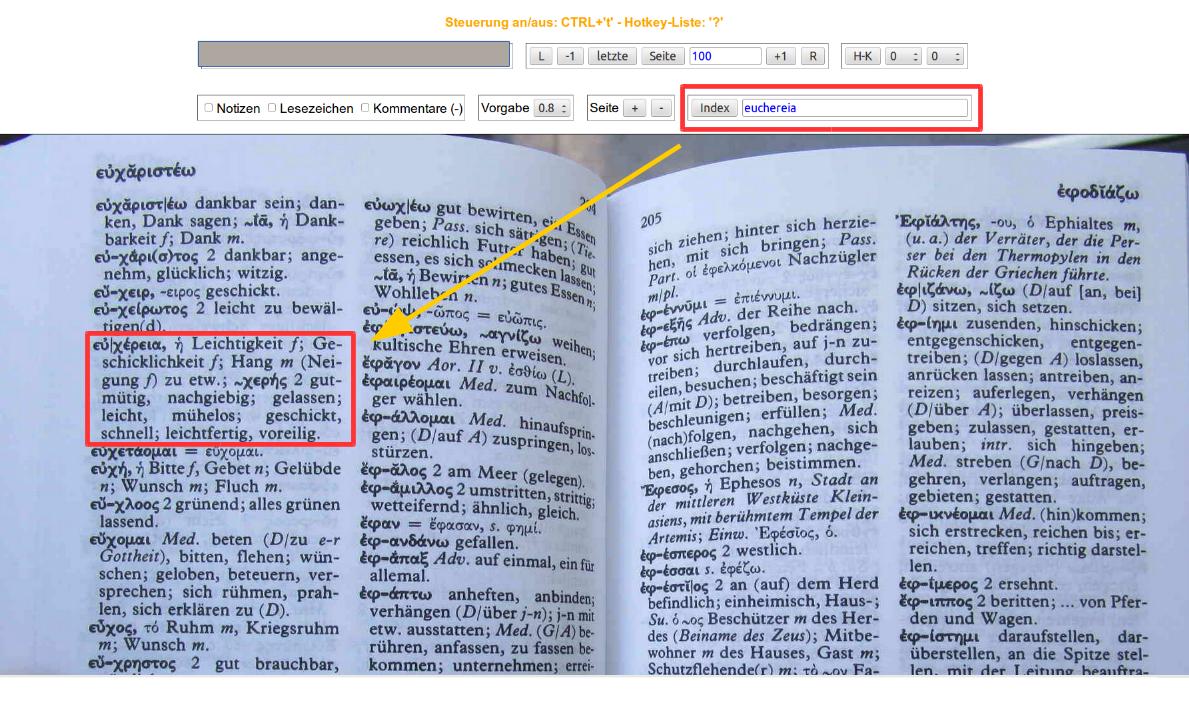
Beide Probleme können wir wiederum mit einem Scanner lösen, welcher nun jedoch nicht Pseudocode auf Unicode abbildet wie im Beispiel der Kommentarfunktion oben sondern alle Zeichenfolgen des Pseudocodes auf genau diejenigen Zeichen des römischen Alphabetes transformiert, deren Stelle derjenigen des codierten Zeichens im griechischen Alphabet entspricht !
Damit erhalten wir folgende Scanner-Konfiguration (Ausschnitt), deren rechte Seite einfach das römische Alphabet darstellt. Die semantisch bedeutsame linke Seite wird also lediglich in ein korrekt sortierbares Schema überführt. Dass letzteres keine sprachliche Bedeutung mehr hat, spielt für das Auffinden der Seitenzahl keine Rolle:
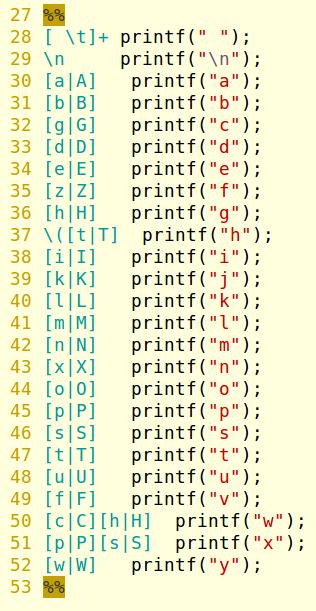
Anhand der ebenfalls pseudocodierten serverseitigen Indexdatei
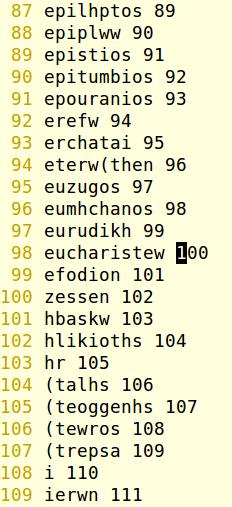
kann die korrekte Seite nun gefunden (und im Folgeschritt dargestellt) werden, indem Suchbegriff und Indexdatei via PHP-Systemcall popen("cat ...) mit Befehlspipe gemeinsam transformiert, sortiert, grepped und auf die resultierende Seitenzahl verdichtet werden, wobei mygreeksort obigen (compiled) Scanner darstellt. Effektiv sortiert wird also nicht die Pseudocode-Darstellunng von Suchbegriff und Index, sondern deren rein numerische Positionsabbildung auf ein Unix-Werkzeugen zugängliches Sortierschema, das römische Alphabet.
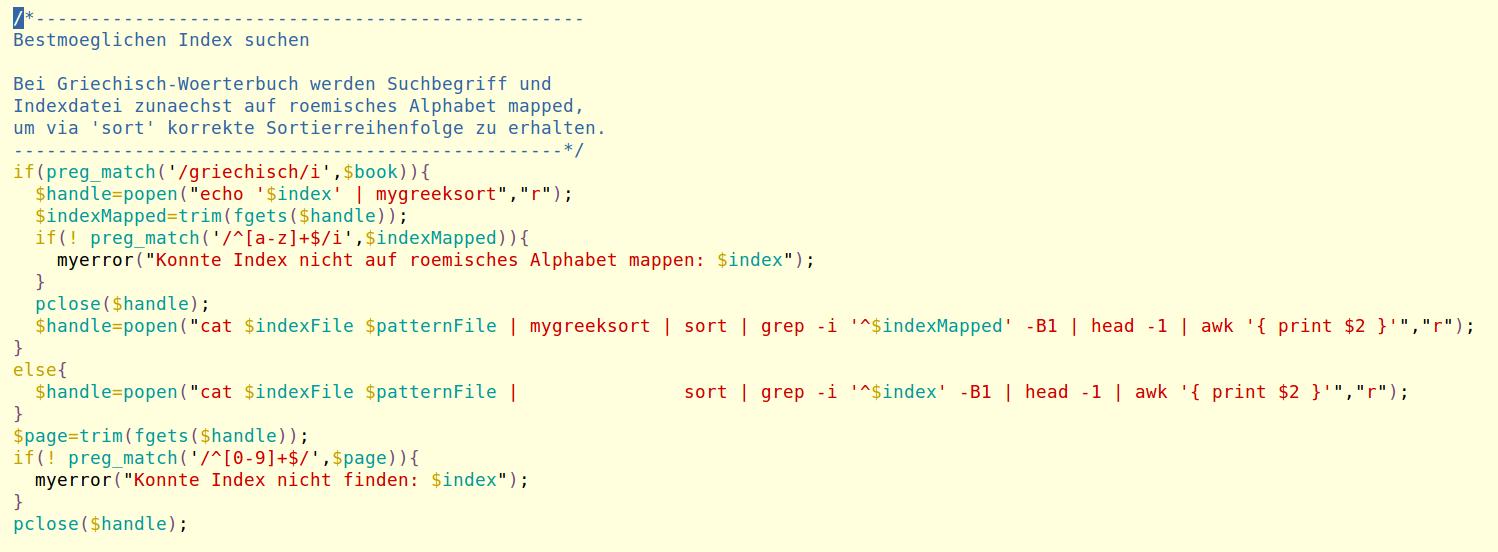
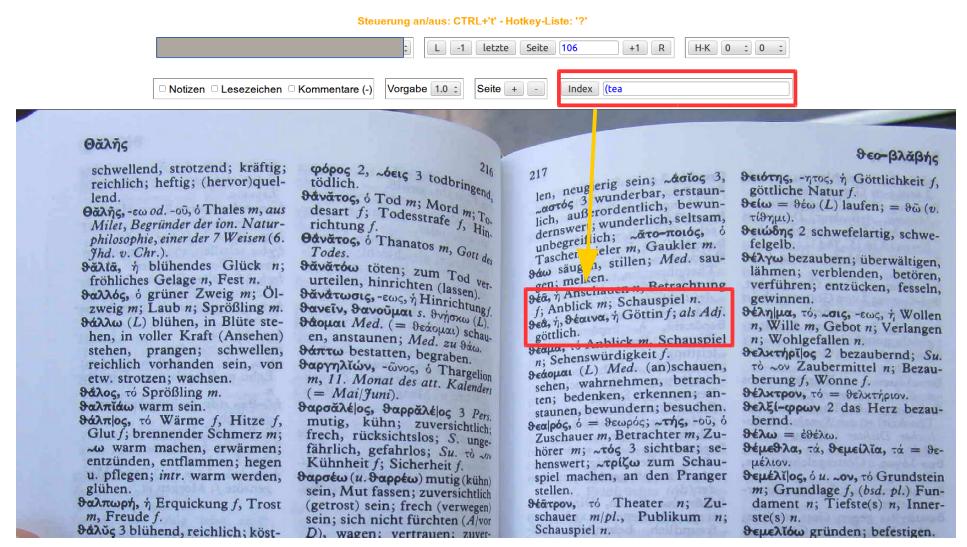
Hier noch ein Abschlussbeispiel, in welchem (t das griechische θ codiert
Wie oben beschrieben wird dazu der eingegebene Pseudocode (tea für die griechische Zeichenfolge theta-epsilon-alpha n die römische Zeichenfolge hea gewandelt, da die Zeichen h-e-a dieselben Positionen im römischen wie vorige im griechischen Alphabet und somit die gewünschte Sortiereigenschaft für die Indexsuche aufweisen.
Erweiterte Funktion
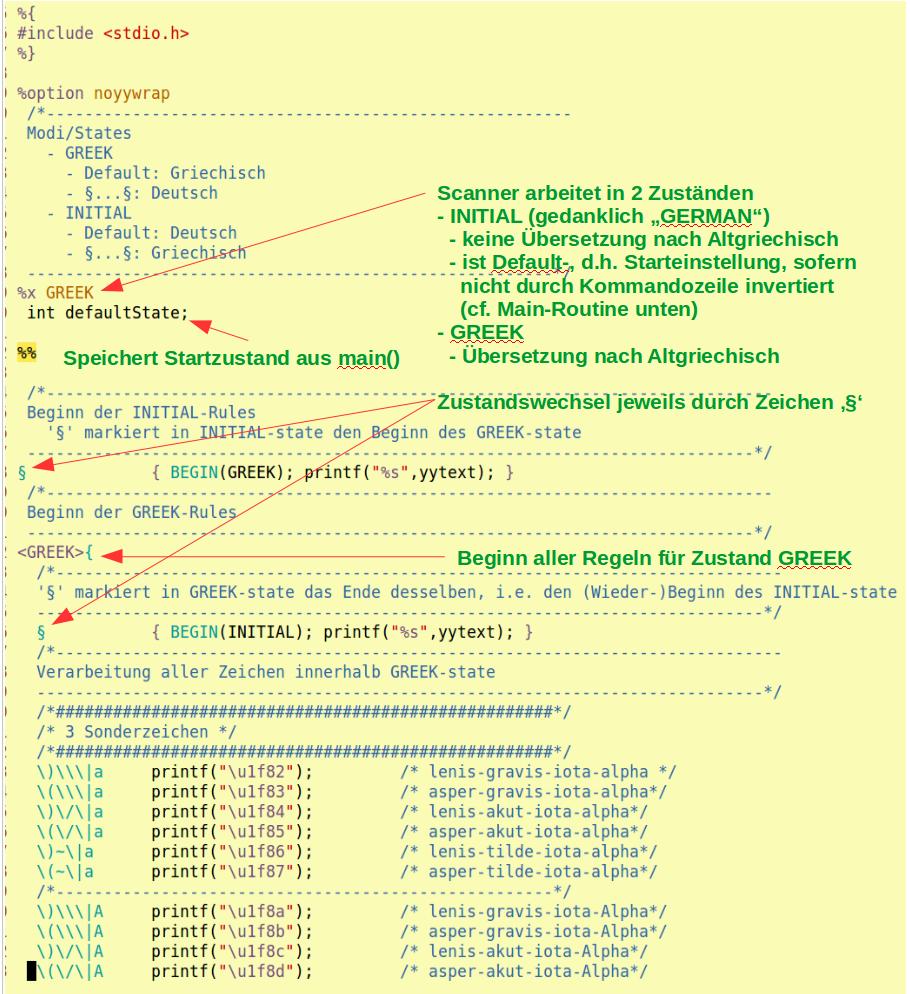
Möchte man z.B. eine Online-Altgriechisch-Grammatik, also eine Website, deren Zeichen zwischen Deutsch und Altgriechisch wechseln mit einfachem Wiki-Markup auf deutscher Tastatur erstellen, erreicht man das mit einer Abwandlung obigen Scanners.Diese
- erlaubt in Texten zeilenübergreifende Kommentare mit den Begrenzern §...§ und 2 Betriebsmodi
- nur Zeichen innerhalb §...§ in Altgriechisch wandeln
- Erstellung des Webseitenhaupttextes mit Griechisch-Einsprengseln
- nur Zeichen außerhalb §...§ in Altgriechisch wandeln
- Generierung von Grammatiktabellen mit deutschen Kommentaren
- nur Zeichen innerhalb §...§ in Altgriechisch wandeln
- arbeitet der Scanner in 2 Zuständen, sogenannten states
-
, welche durch Kommandozeilenparameter in der Routine main() alternativ als Startwert gesetzt werden.

-
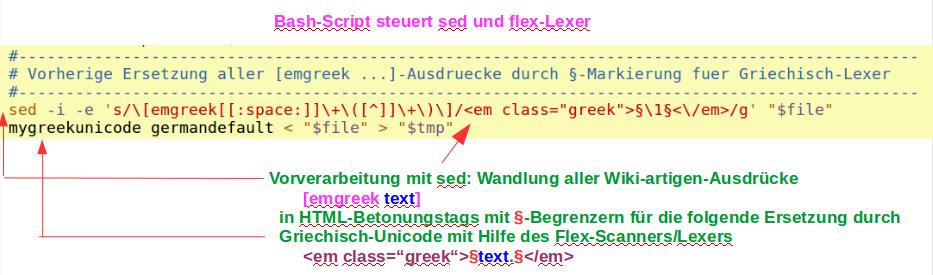
Nach Vorverarbeitung des Wiki-Markup und Aufruf des Scanners via bash-Script
-
wird etwa folgender Beispielsatz 2-stufig transformiert.
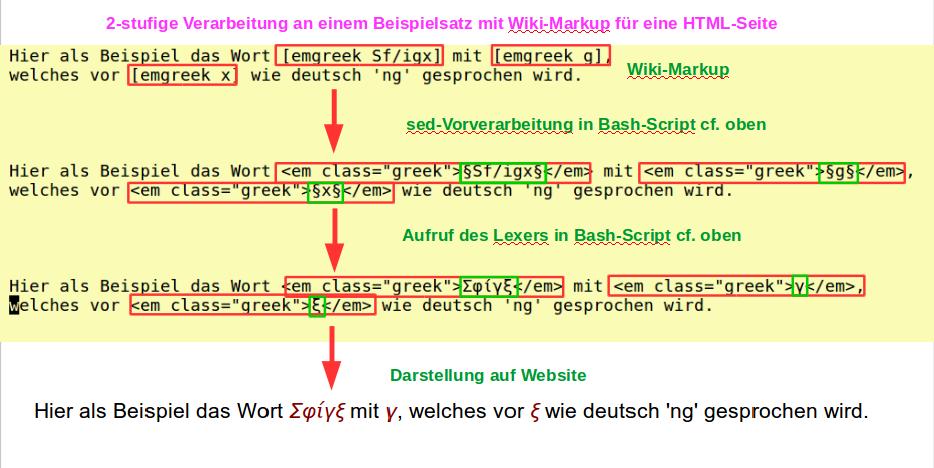
- Erstellt werden können so Haupttexte (Default: Deutsch, Kommentare: Griechisch) oder Tabellen (Default: Griechisch, Kommentare: Deutsch) (cf. (Grammatik